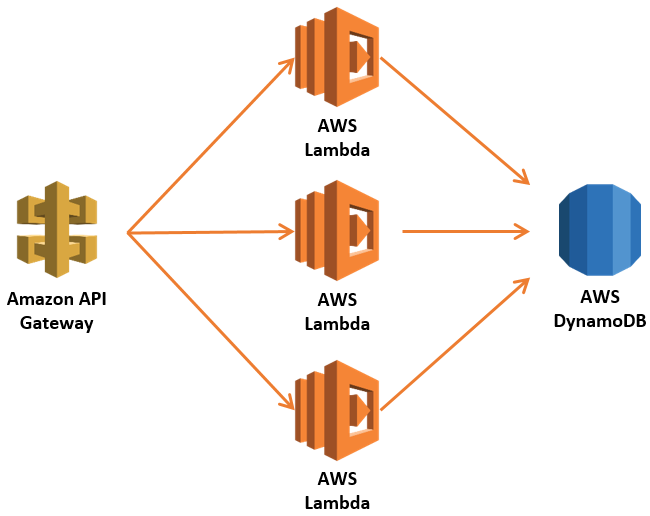
Generating Signed S3 URL's
Generating Signed S3 URL's
Updated 2 years ago Published 2 years ago

One of the great but often forgotten features provided by S3 is the ability to generate temporary signed URL's that can be used to view, upload and delete files from a bucket.
Signed URL's are a secure and easy way to provide a temporary upload path for a client without the need to build any intermediate services to handle the uploads for you.
In this post we will cover how you can provision a signed URl for a file already present within a bucket, You can currently only create signed URl's to GET a file via the AWS cli.
You will need to ensure you have the AWS cli installed.
aws s3 presign s3://devnotnull.com-signed/$FILE --expires-in 604800